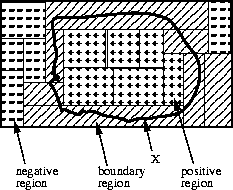
- Figure 34. Approximation region of the set X (from Reduct System, 1993:App.212)
The results are compared with respect to the groups of speakers and the vowel categories, using a two-way ANOVA analysis. The classification of the speakers given by phoniatric examination (normal, breathy, recurrent nerve paralysis with and without compensation and chordectomy) is related to the quantitative experiment data. Rules for the data-based classification are prepared using the rough sets technique (cf. Slowinski, 1992; for a lit. survey see: Reduct System Inc, Datalogic: Appendix 1, 1993 or open http://ils.unc.edu/~wongs/info_retrieval/annotated/roughset.html). In a pilot experiment (Marasek, 1995b) the rough set approach was verified with very good results.
The rough sets (proposed by Pawlak,1991) is one of the techniques for the identification and recognition of common patterns in data, especially in the case of uncertain and incomplete data. The mathematical foundations of this method are based on the set approximation of the classification space.
Within the framework of rough sets the term "classification" describes the subdividivision of the universal set of all possible categories into a number of distinguishable categories called elementary sets. Each elementary set can be regarded as a rule describing the object of the classification. Each object is then classified using the elementary set of features which can not be split up any further, although other elementary sets of features may exist (Reduct System, 1993). In the rough set model the classification knowledge (the model of the data) is represented by an equivalence relation IND defined on a certain universe of objects U. The pair of the universe objects U and the associated equivalence relation IND forms an approximation space. The approximation space gives an approximate description of any subset x of U.
The classification knowledge can then be then presented as a set of cells of the surface U, on which the set of the objects which are the subject of classification forms the region X (as depicted in Fig.34). If the cells are completely included in the set X, then the objects of the set X can be classified without any ambiguity based on their elementary sets (they are marked with "+" in Fig.34). There are also elementary sets which lie completely outside the set X. They represent the negative knowledge about the set X. The elements of X do not possess the features described by the elementary sets that are placed in the negative region of the set X (denoted with "-" in Fig.34). In Fig.34 the boundary regions are additionally marked.
The boundary region of any set X with respect to classification knowledge IND is the union of those elementary sets of IND which are partially, but not entirely included in X (Reduct System, 1993:App.2:10). If only positive and negative regions were non-empty, then classification knowledge would be perfect and precise - all cases could be classified without errors. But quite often, our knowledge about the observed phenomenon is incomplete. This is described by the boundary regions in the universe U. Those representations allow an approximate inferrence in the sense of the region approximation.
|
The positive region of the approximation is also called the lower approximation of the set X. The union of the positive and the boundary regions constitutes the upper approximation. The upper approximation contains all data which can possibly be classified as belonging to the set X. The accuracy of the approximation is measured as the ratio of the lower and the upper approximations sizes. The ratio is equal to 1, if no boundary region exists, which indicates a perfect classification. In this case deterministic rules for the data classification can be generated.
Another aspect of the rough sets method is to simplify the set of parameters used for data classification (elementary sets). This can be achieved by concatenation of the elementary sets, but it has to be done in such a manner that the accuracy of the approximation remains unchanged. In terms of the graphic representation in Fig.34, this corresponds to remove the lines between the elementary sets. The results are thus less detailed, coarser and constitute a rougher representation of the classification knowledge (the cells in Fig.34 are larger and smaller in number). These rearrangements of cells result in fewer, stronger, but perhaps less precise rules. The level of cell grouping is controlled by the roughness parameter. Roughness varies between the values 0 and 1. When roughness is set to 0, the classification is precise. An increased level of roughness results in a more global but probably less precise classification.
As the roughness of the knowledge grows, the boundary region vanishes since it is being incorporated into the positive region of the classification. As a result, a "deterministic" classification can be done, although the data representation is now rough. Whether a cell is considered positive or negative (within or outside of the set X) depends on the rule precision threshold. If the probability of the classification rule (Reduct System, 1993:App.2:85) exceeds a given threshold, the rule is accepted, otherwise it fails. The rule precision threshold can be set in the range 0...1. The precise rules have a rule precision threshold equal to 1.
The rough sets approach to data classification is often referred to as a machine-learning procedure for incomplete or imprecise data and was extensively tested in various scientific domains (Slowinski, 1992). It should be noted that other techniques of approximate reasoning exist and that their results are comparable to those yielded by the rough sets. Rapp (1994, 1997) shows that the rough set classfication can be sucessfully used in the classification of notoriously imprecise prosodic parameters such as stress, pitch accent and boundary tone. He also argues that the rough sets classification is weakly equivalent to other machine-learning classification methods.
The data collected in this experiment is labelled according to the phoniatricians' decisions regarding the categorization of all speakers and all vowels and then inserted into the rough sets inference engine4. Relationships between data are indicated in the form of rules at a given level of roughness and for a certain rule precision threshold. Additionally, for each rule an attribute strength report is generated which shows the relative importance of a given attribute (in this case the name of the variable) for a certain rule. The attribute strength values range from 0 (weakest) to 1 (strongest). If the attribute strength is low, the data model, which is composed of the established rules has poor predictive capability. If the data shows strong patterns, the relative attribute strength will be high. The attribute strength provides a preliminary measure of the classification quality.
The rule strength report constitutes the last part of the rough sets classification. It is a listing of the cases supporting a given rule. The more cases support a rule, the stronger it is.
The established rules can then be tested using the leave-one-out method. Model validation with the leave-one-out method comprises random splitting of the data into training and test data. The model generated through the use of the training data is then tested on the second set of data. However, in cases of small or incomplete data sets, the selection of the test data may disturb its patterns. Thus, it is better to use only a small amount of data for the purpose of testing. In the leave-one-out method only one individual token is chosen. The rules derived from the remaining cases are used to predict the decision on the categorization of the test case. This procedure is repeated for all cases. However, this method of model testing may be used only for non-rough rules (roughness=0), therefore the generation of the precise model is stiil necessary.
4 Datalogic, Reduct System Inc.
![]()
![]()
![]()
![]()